
Designing Big Data architecture is no mean feat; rather it is a very challenging task, considering the variety, volume and velocity of data in today’s world. Coupled with the speed of technological innovations and drawing out competitive strategies, the job profile of a Big Data architect demands him to take the bull by the horns.
What’s the Plan
Take a deep dive into orchestrating big data solutions with celebrated business analyst training courses in Gurgaon.
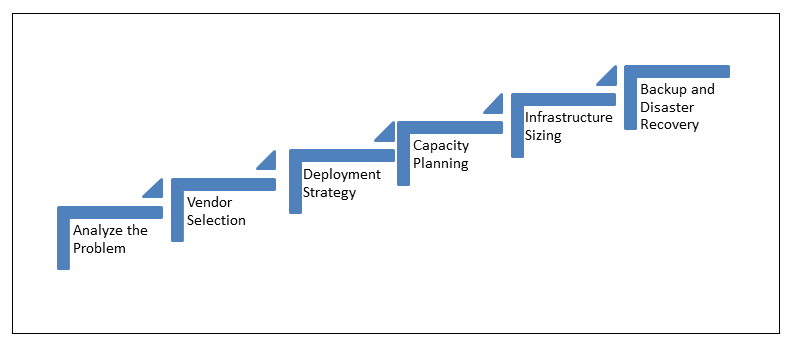
Get Through the Kernel of the Business Problem
Analyze the business problem, and identify whether it is a Big Data related problem or not. It won’t be prudent to just look at the sheer volume or cost factor, as they alone can’t be the deciding factors. Various other factors, like variety, volume, velocity, processing time or challenges within the current system must be given a look, as well.
5 Common Use Cases
- Data Offload/ Data Archival – Though it is a clumsy process and involves pretty long SLA’s for data retrieval from tapes, it is one of the most common methods of backup. On the other hand, Hadoop enables storage of humongous amounts of data over the years at bare minimum costs.
- Process Offload – Offload jobs that exhaust expensive MIPS cycles or devour extensive CPU cycles on the present systems.
- Data Lake Implementation – Data Lakes are amazing to store and process vast pools of data.
- Unstructured Data Processing – Big Data technologies facilitate storage and processing of any amount of unstructured data, natively.
- Data Warehouse Modernization – Operational efficiency is increased by integrating the capabilities of Big Data and your data warehouse.
Selection of Vendor for the Hadoop Distribution
Depending on their personal biases, market share of vendors or any sorts of existing partnerships, clients drive vendor selection for Hadoop distribution, often. Cloudera, Hortonworks, BigInsights and Mapr are some of the vendors for Hadoop distribution.
Deployment Strategy
Deployment strategy is crucial, as it ascertains whether it will be on premise, cloud based or a mixture of both. Though each one comes with its own pros and cons:
- Banking, insurance and healthcare customers prefer an on premise solution, as the data doesn’t leave the premise. But, the hardware procurement and maintenance cost would soar high, as well as effort and time.
- A cloud based solution is undoubtedly the most cost effective option, because it offers a lot of flexibility in terms of scalability and reduces maintenance and procurement overhead.
- A mix deployment strategy entails some tidbits of both worlds, and is great to retain PII data on premise and throughout the cloud.
Capacity Planning
Important factors to be considered:
- Data volume for one-time historical load
- Daily data ingestion volume
- Retention period of data
- HDFS Replication factor based on criticality of data
- Time period for which the cluster is sized (typically 6months -1 year)
- Multi datacenter deployment
The Size of Infrastructure Matters
Capacity Planning plays a dominant role in infrastructure sizing. The decision to use what type of hardware to be used, including the number of machines, CPU, memory, etc. and determination of the number of clusters/environment required are to be factored out by infrastructural sizing.
Take a look at the important considerations:
- Types of processing Memory or I/O intensive
- Type of disk
- No of disks per machine
- Memory size
- HDD size
- No of CPU and cores
- Data retained and stored in each environment (Ex: Dev may be 30% of prod)
Backup and Disaster Recovery Planning
Backup and disaster recovery is a significant portion of planning, and includes the following concerns:
- The criticality of data stored
- RPO (Recovery Point Objective) and RTO (Recovery Time Objective) requirements
- Active-Active or Active-Passive Disaster recovery
- Multi datacenter deployment
- Backup Interval (can be different for different types of data)
DexLab Analytics is a powerful learning community that offers exclusive Big Data Hadoop training. For more information, visit our website.
Interested in a career in Data Analyst?
To learn more about Machine Learning Using Python and Spark – click here.
To learn more about Data Analyst with Advanced excel course – click here.
To learn more about Data Analyst with SAS Course – click here.
To learn more about Data Analyst with R Course – click here.
To learn more about Big Data Course – click here.
Comments are closed here.