
Apache Spark is designed to make data science easier. Obviously, the breed of data scientists leverages machine learning – through a set of tools, techniques and algorithms that helps learn from data. Often, these algorithms are iterative, Spark speeds up iterative data processing boosting implementation and analysis.
Introducing Apache Spark
Equipped with a sophisticated and expressive development API, Apache Spark is cutting edge open-source distributed general-purpose cluster computing framework. It lets data specialists to effectively execute machine learning, streaming or SQL workloads. It comes with in-memory data processing engine combined with an advanced APIs for top-notch programming languages, including R, Scala, SQL, Python and Java.
It can also be defined as a distributed, data processing engine ideal for streaming and batch modes exhibiting graph processing, SQL queries and machine learning.
To learn Apache Spark, reach us at DexLab Analytics. Being a premier Apache Spark training institute in Gurgaon, we offer the right courses fitted for you!
History
To better understand what Spark offers, it is important to take a look back at the history of Spark. MapReduce used to dominate the sphere before Spark came into existence. It was a robust distributed processing framework that empowered Google to index humongous volume of content on the web, across huge clusters of myriad commodity servers.
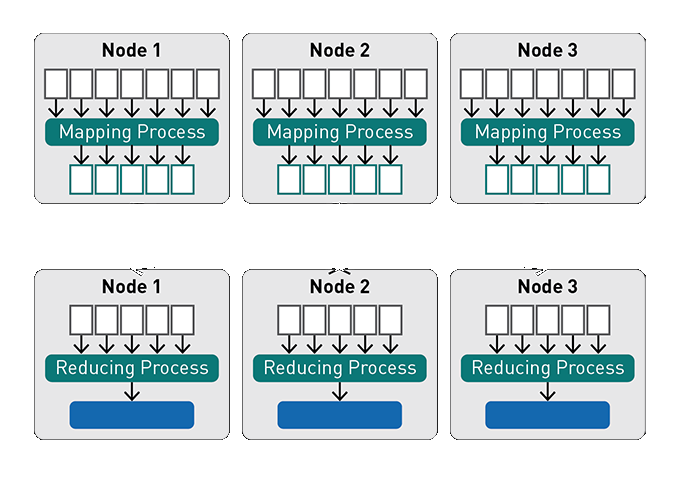
A year after a white paper on MapReduce framework was published by Google, Apache Hadoop came into being – the latter was launched in the year 2009 as a project within the AMPLab at the University of California, Berkeley. However, it came into limelight in 2013 – when Apache Software Foundation acquired it as their incubated project and since then Spark has become the most influential project initiated by the Foundation. The community surrounding the project has been flourishing since then – and it includes notable individual contributors and corporate bigwigs, such as IBM, Huawei and Databricks.
Why Did Spark Replace MapReduce?
Interestingly, Spark was developed to keep the advantages of MapReduce intact, while making it easier to implement and more productive.
Benefits of Spark over MapReduce:
- Execution in Spark is pretty faster; it caches data in memory from various parallel operations, while MapReduce focuses more on writing and reading from disk.
- Across JVM processes, Spark executes multi-threaded tasks, seamlessly, whereas MapReduce feels heavier amidst JVM processes.
- Undeniably, Spark supports quick startup, better parallelism and improved CPU utilization.
- For an enriching functional programming experience, Spark is preferable.
- Notably, Spark is better for using parallel processing of distributed data in association with iterative algorithms.
Who Uses Spark?
Digital natives, like Huawei and IBM, have already invested hugely on Spark adoption, integrating it with their own products. Also, an increasing number of startups have started building businesses around Spark. Prominent Hadoop vendors are – MapR, Cloudera, Databricks and Hortonworks – they have all shifted their focus to support YARN-based Apache Spark.
Web-based organizations, like Chinese search engine giant Baidu, an e-commerce setup Taobao and a social networking company Tencent – all have embraced Apache Spark and generates tremendous amounts of data per day on countless clusters of compute nodes.
Are you looking for the best Apache Spark training center in Gurgaon? You are at the right place! Hope we can help you.
The blog has been sourced from ― mapr.com/blog/spark-101-what-it-what-it-does-and-why-it-matters
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course – Enrol Now.
To learn more about Data Analyst with R Course – Enrol Now.
To learn more about Big Data Course – Enrol Now.To learn more about Machine Learning Using Python and Spark – Enrol Now.
To learn more about Data Analyst with SAS Course – Enrol Now.
To learn more about Data Analyst with Apache Spark Course – Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course – Enrol Now.
Apache Spark, Apache Spark Certification, Apache Spark Courses, Apache Spark Training, Apache Spark training center, Apache Spark Training Institute
Comments are closed here.